

USPTO Releases Video of AI Tool 'SCOUT'
GPT, Gemini, Claude and Llama available...

Following months of development and internal testing, the United States Patent and Trademark Office (USPTO) recently released a detailed 5-minute demonstration video (ver. 1, ver. 3) of its Searching, Consolidating, Outlining, and Understanding Tool, commonly referred to as SCOUT.
Initially reported in mid-2025 as a secure generative artificial intelligence application for agency staff, the platform has matured into a comprehensive portal. The newly available footage (appearing below) provides intellectual property professionals a transparent view into the interface patent examiners and agency personnel will soon utilize in their daily operations.

The SCOUT system appears engineered to augment routine tasks. At the same time, the deployment presents new procedural considerations for practitioners interacting with the office. By examining the visual evidence and stated functionalities, patent practitioners can better anticipate the ways this technology might influence patent prosecution.
The initiative aligns with the agency’s broader modernization efforts. Former Chief Information Officer Jamie Holcombe previously emphasized a philosophy of acting quickly and taking measured risks with technology procurement. Under his directive, the Office of the Chief Information Officer moved the agency to cloud-based infrastructure.
The SCOUT platform represents the culmination of these efforts, building upon earlier tools like “More Like This Document” and the automated “Similarity Search.” The transition from limited search algorithms to generative text models marks a significant shift in the examination process.
In July 2025, reports emerged indicating the agency made artificial intelligence similarity checks mandatory for examiners evaluating all new patent applications. Whether fruitful or not, these mandatory integration laid the groundwork for more advanced systems. The SCOUT application builds upon that foundation, shifting the focus from simple prior art retrieval to advanced data analysis and content generation.
A Multi-Model Approach: Accessing Diverse Engines
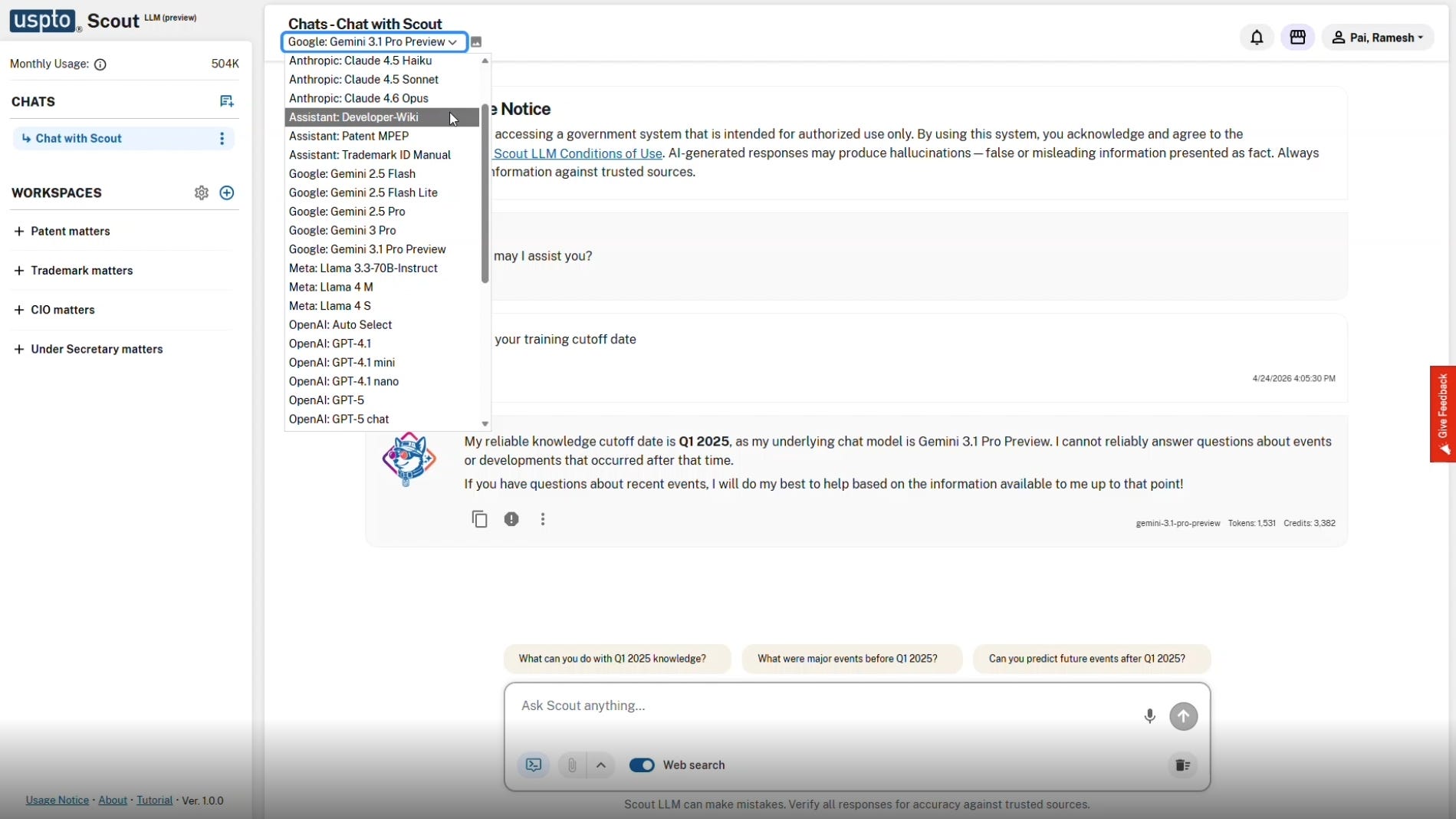
One of the most striking aspects of the SCOUT platform is its model-agnostic architecture. Rather than relying on a single proprietary engine, the interface features a dropdown menu allowing users to select from a wide array of advanced language models.
The video shows options spanning multiple industry leaders. Users can select Google’s “Gemini 3.1 Pro Preview,” Anthropic’s “Claude 4.6 Opus,” Meta’s “Llama 4 S,” or OpenAI’s “GPT-5.” The inclusion of models like “Claude 4.5 Haiku” and “Gemini 2.5 Flash Lite” suggests options for less computationally intensive tasks.
This flexibility indicates the USPTO is working to prevent vendor lock-in. Providing access to various models means examiners can select the engine best suited for a specific technical inquiry.
Certain models may perform better on biotechnology sequence analysis, whereas others might excel at parsing intricate software logic. In addition to commercial models, the menu features specialized internal assistants.
Options such as the “Assistant: Patent MPEP” and “Assistant: Trademark ID Manual” are visible in the interface. These dedicated assistants likely draw upon the agency’s nine petabytes of curated internal data to provide highly specific procedural guidance. This aligns with early 2025 reports suggesting SCOUT would help users search the Manual of Patent Examining Procedure to quickly find answers to procedural questions.
The interface shows a user interacting with the Gemini 3.1 Pro Preview model. In the chat window, the system explicitly states, “My reliable knowledge cutoff date is Q1 2025, as my underlying chat model is Gemini 3.1 Pro Preview.” The system informs the user it cannot reliably answer questions about events or developments that occurred after that time.
This temporal limitation highlights the operational necessity of providing multiple models and web search integration. Different models possess varying cutoff dates and training datasets. The voiceover indicates that examiners can switch to an alternate system or enable live internet access to investigate a recently published academic paper or a newly released software product.
Strict Conditions of Use and Data Privacy
The newly revealed “Conditions of Use for USPTO Scout LLM” document provides a stark look at the boundaries placed upon examiners. The system is clearly marked as an Alpha testing environment. A prominent warning directs beta users away from the alpha platform, stating “!! SCOUT LLM (PREVIEW) is for testing purposes only.”
Protecting confidential application data under 35 U.S.C. § 122(a) remains a top priority. The first rule in the conditions dictates, “I will not enter or upload any Personally Identifiable Information (PII), confidential, or sensitive information into Scout LLM.”
The document provides a guiding principle: users should only upload information they “would be comfortable with or authorized to enter into a public (non-USPTO) website like Google or Bing.” The instructions offer specific examples, noting that information from published applications is acceptable, but “Unpublished applications and file wrappers would not be acceptable and must not be used within or uploaded to Scout LLM.”
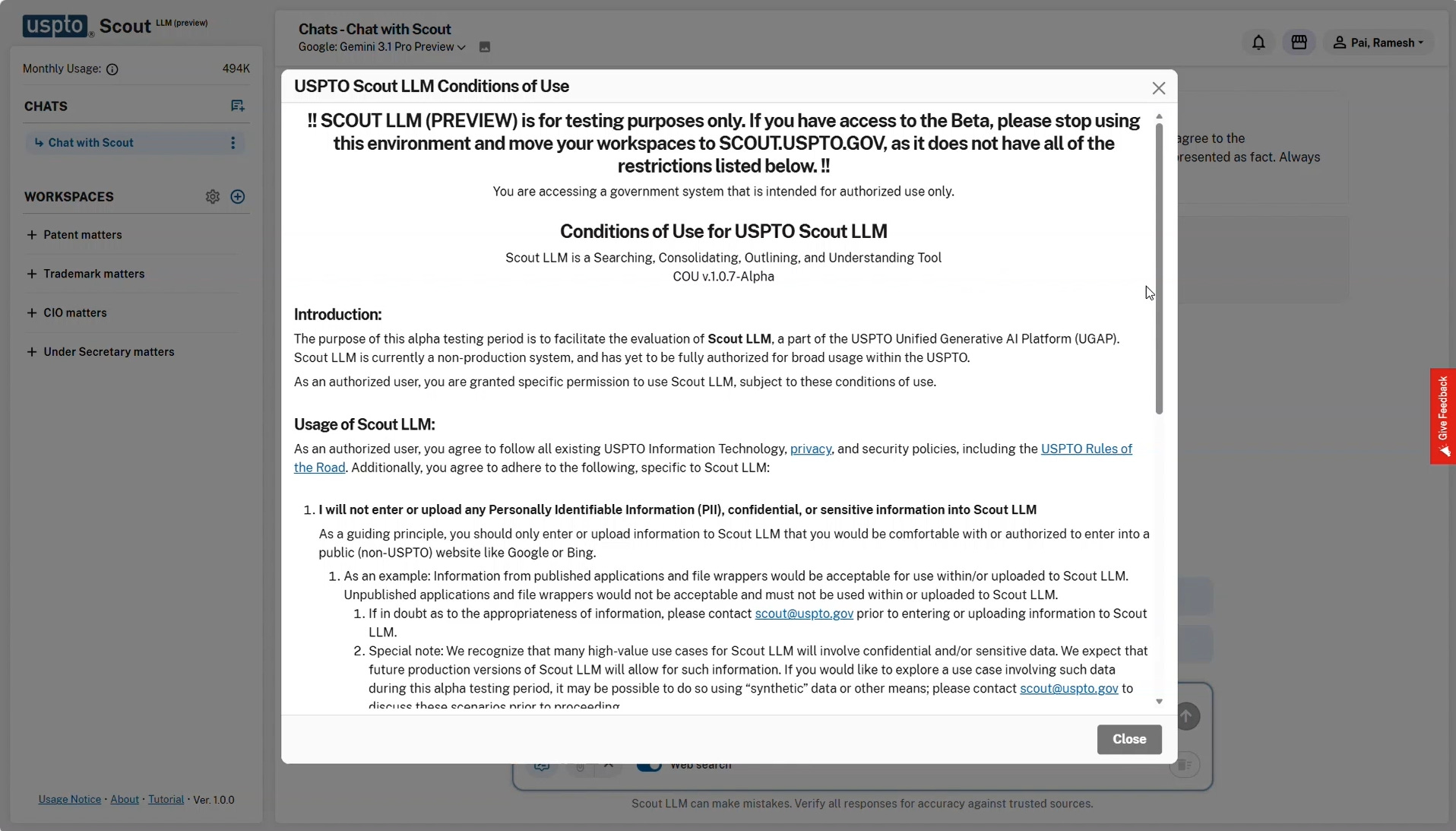
The agency acknowledges this limitation hinders utility. A special note in the conditions states, “We recognize that many high-value use cases for Scout LLM will involve confidential and/or sensitive data.”
The text projects that future production versions will allow for such information. For the current testing phase, the document suggests using “synthetic data or other means” to explore high-value use cases securely.
An observable feature previewed in the demonstration is a toggle for web search. When activated, this mode allows the selected model to access the internet for current information. The activation of this feature triggers immediate and strict security protocols.
The system displays a stark warning when web search is enabled. The text states, “In this mode, attachments and collections will be disabled, and any files you’ve uploaded to this thread or workspace will not be accessible to Scout LLM.”
Testing, Monitoring, and Hallucination Warnings
The USPTO makes it abundantly clear that SCOUT is not a flawless oracle. The system is heavily guarded with usage notices and liability disclaimers.
The conditions of use mandate that personnel report potential security issues immediately, including “aberrant outputs containing nonsensical symbols and/or content that encourages you to act in a way that violates laws, regulations, or agency policies.”

A dedicated section details the risks of generative AI technology. The agreement requires users to acknowledge that the systems may produce “hallucinations” which are defined as “outputs that appear plausible but are factually incorrect, misleading, or nonsensical.”
The document notes these hallucinations can arise from limitations in the AI model’s training data or inherent biases in its algorithms. The tutorial screens outline that the system may struggle with “Interpreting ambiguous queries” and is not reliable for “Making ethical, moral, or value-based judgments.”
The system dictates its own role in the workflow. The tutorial text instructs users to “Use Scout to help generate ideas and drafts — not to produce final answers or finished work.” Authorized users must “critically evaluate and verify any information generated by AI systems against official sources.” The examiner retains final authority and accountability.
The user must agree: “I accept full responsibility and accountability for actions and decisions informed by AI use, and will exercise independent judgment and discretion to make sound decisions on behalf of the USPTO.”
To enforce these rules, the USPTO indicates that it implements strict oversight. Personnel must consent to monitoring, acknowledging that “any information entered, uploaded, or shared with Scout LLM may be subject to access by authorized personnel for monitoring, auditing, or compliance purposes.”
Interface, Prompts, and Document Ingestion
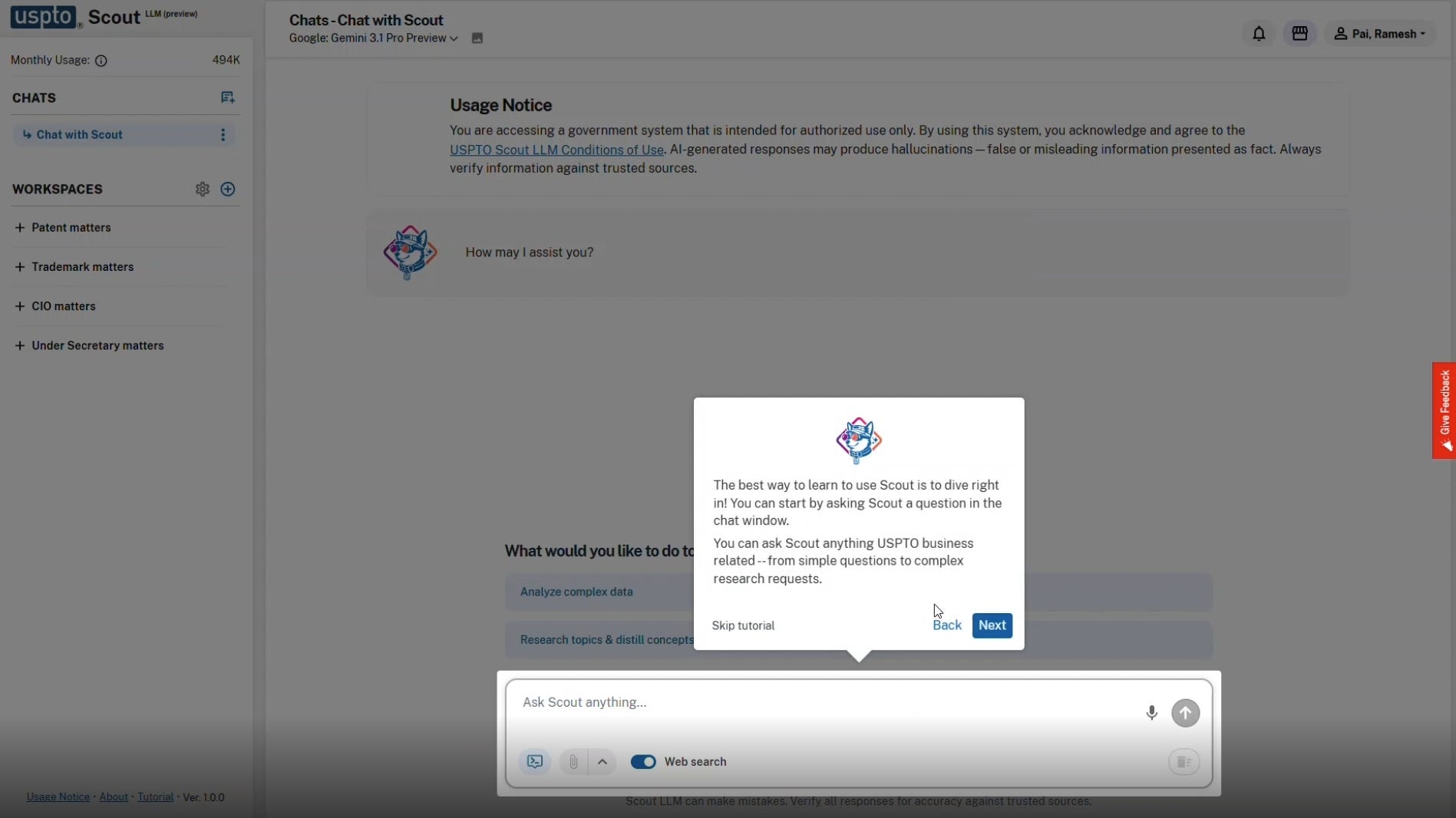
The interface is structured to lower the barrier to entry for staff members. A prominent greeting window encourages users to begin immediately, stating, “The best way to learn to use Scout is to dive right in! You can start by asking Scout a question in the chat window.”
The text notes that staff can ask “anything USPTO business related--from simple questions to complex research requests.”
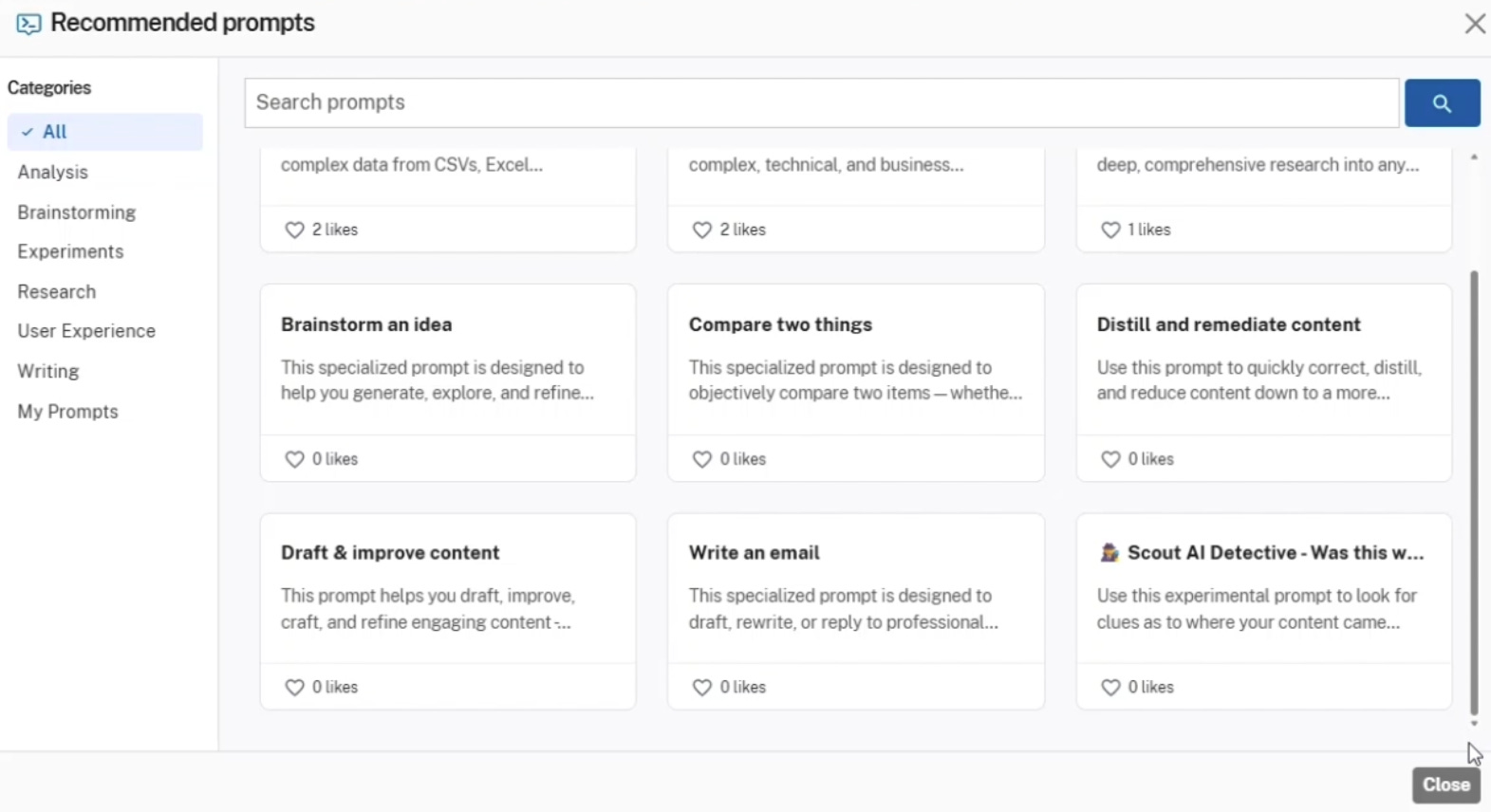
To facilitate user interaction, the portal includes a recommended prompts library. This library is categorized by functions such as Analysis, Brainstorming, Experiments, Research, User Experience, and Writing. Pre-configured prompt cards are available to guide users.
Titles include “Draft & improve content,” “Distill and remediate content,” and “Scout AI Detective.” The prompt descriptions suggest the agency expects SCOUT to assist in synthesizing highly technical data, drafting reports, and potentially formulating portions of office actions.
The “Scout AI Detective” prompt points toward applications in prior art investigation and claim analysis.
The interface includes a “Memory” personalization setting to adapt the system to individual staff members. Enabling this preview feature permits the system to learn from ongoing interactions.
The tool builds a profile of the user’s specific working style and preferences to deliver targeted, relevant responses over time. Users retain the option to clear this memory cache at any point via a “Reset Memory” function.
The platform supports extensive data ingestion. A file management window details the upload capabilities. Personnel can process up to 50 files simultaneously. Each text file is capped at 15MB. The system supports text extraction from standard documents and can transcribe audio and video files up to 500MB in size.
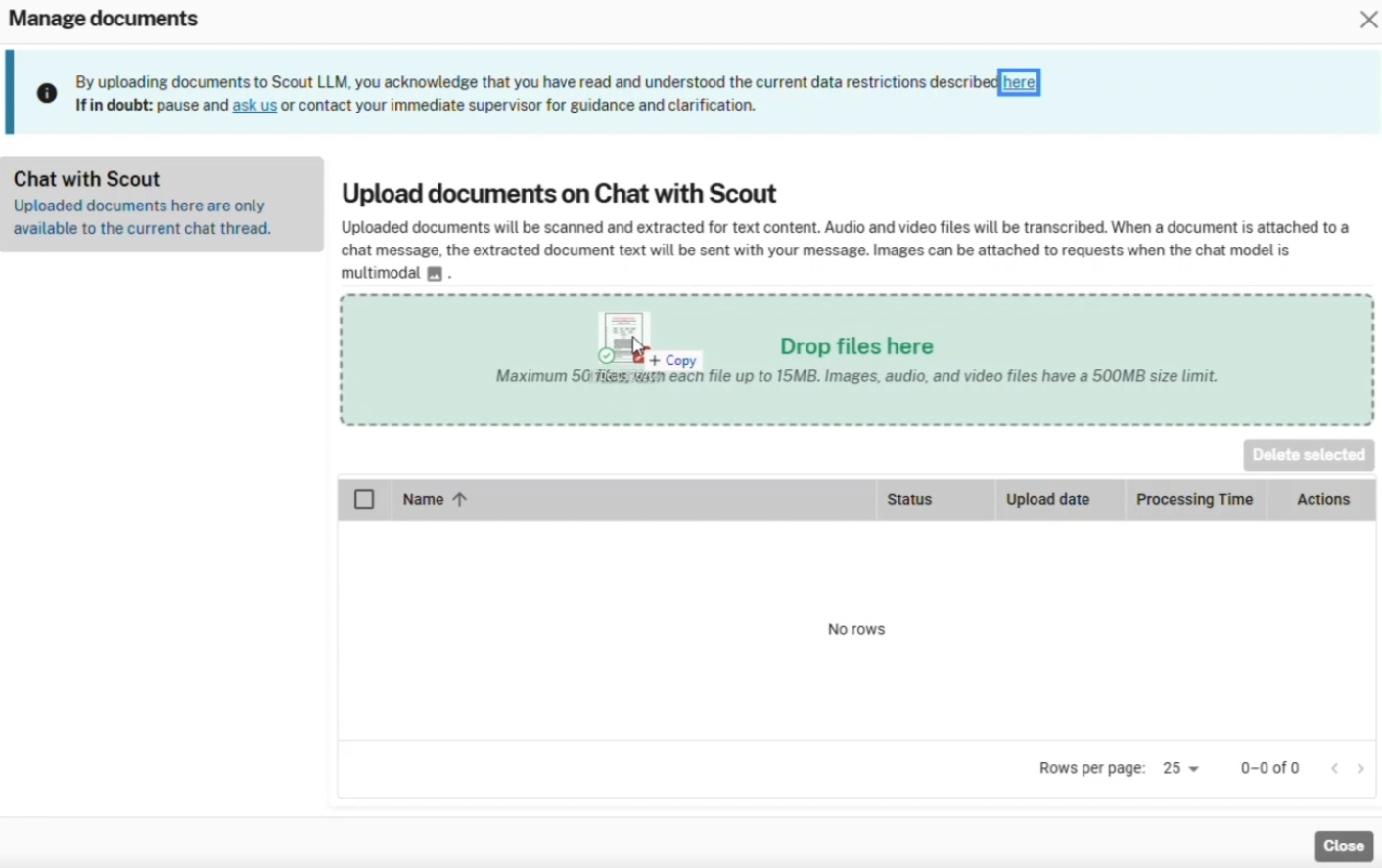
This capable ingestion mechanism means examiners can feed substantial amounts of reference material into the model for summarization or comparison.
While it would likely be mostly PDF files, perhaps an examiner reviewing a lengthy video exhibit or a voluminous software specification could theoretically upload the entire file for automated transcription and subsequent analysis by the selected language model.
Web Search Integration and Information Security
An observable feature previewed in the video is a toggle for web search. When activated, this mode allows the selected model to access the internet for current information. The activation of this feature triggers immediate and strict security protocols.
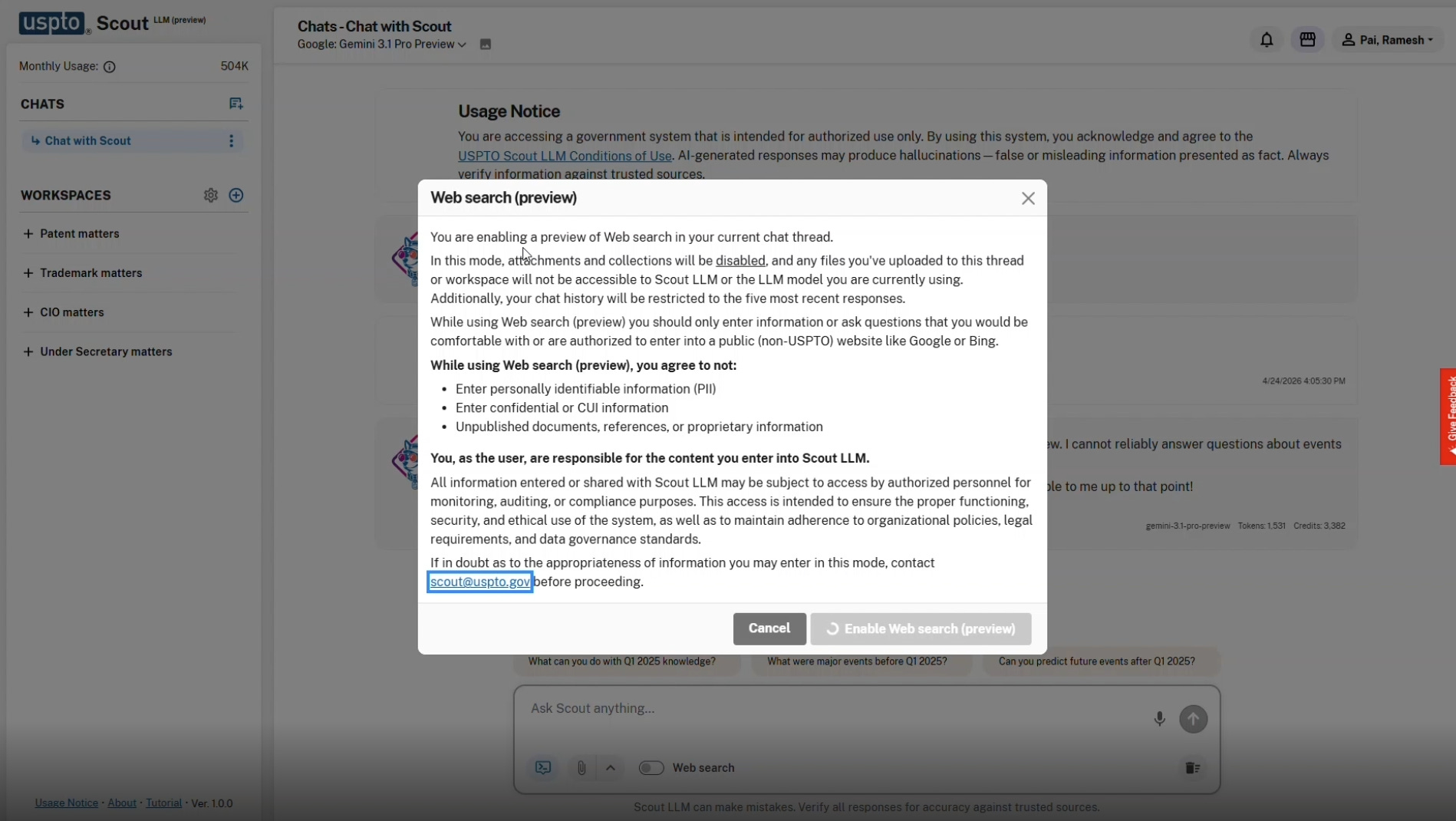
The system displays a stark warning when web search is enabled. The text states, “In this mode, attachments and collections will be disabled, and any files you’ve uploaded to this thread or workspace will not be accessible to Scout LLM.”
The notice explicitly instructs users to “only enter information or ask questions that you would be comfortable with or are authorized to enter into a public (non-USPTO) website like Google or Bing.”
Personnel must agree to strict prohibitions. Users agree not to enter “personally identifiable information (PII).” They agree not to enter “confidential or CUI information.” They must refrain from entering “Unpublished documents, references, or proprietary information.”
This rigid segregation between internal data processing and external web searching reflects the agency’s ongoing concern regarding data leaks. Protecting confidential application data under 35 U.S.C. § 122(a) remains a top priority.
The USPTO system appears engineered to prevent the inadvertent transmission of unpublished patent data to commercial web environments.
Benefits, Challenges, and Risks
The deployment of the SCOUT platform presents several potential advantages for the patent ecosystem. Supplying examiners with advanced synthesis and summarization capabilities could decrease the time required to comprehend dense, highly technical prior art.
The availability of specialized tools like the Patent MPEP assistant may increase the consistency of procedural applications across different art units. If examiners can synthesize information more efficiently, this could theoretically reduce application pendency. This efficiency could improve the overall quality of prior art searches, especially when evaluating intricate software or biotechnology filings.
The transcription features for audio and video files provide a new method for handling non-traditional exhibits. The (closed) cloud architecture provides the significant processing power required to run instances of GPT-5 or Llama 4 securely with (seemingly) minimal latency, establishing a foundation for future capability expansions.
Still, adopting this technology introduces significant workflow hurdles. Examiners are already operating under strict production goals. Integrating a multifaceted tool into standard examination practices requires comprehensive training. If an examiner uses the recommended prompt to analyze a claim limitation, they must dedicate time to independently verify the model’s logic.
Reviewing generated text for hallucinations or logical leaps demands a different cognitive skill set than traditional document review. Balancing the efficiency gains of automated drafting against the required time for careful human review will be a continuing problem for agency management.
Practitioners may face new burdens in deciphering whether a rejection was formulated by a human or generated by an algorithm.
The primary risks center on confidentiality and over-reliance. The system architecture aims to prevent data leakage. This is evident in the strict web search limitations. In spite of these technical controls, the human element remains a variable. An accidental copy-paste of unpublished claim language into a web-enabled prompt could result in a significant confidentiality breach.
The psychological phenomenon of automation bias is a persistent threat. Overworked personnel might accept generated arguments or prior art summaries without adequate scrutiny. For patent practitioners, this introduces the risk of receiving office actions containing superficially plausible but technically flawed rejections. Rebutting these algorithmically generated arguments will necessitate more time and client resources.
A secondary risk involves transparency and the opaque nature of these algorithms. Understanding the specific logic the model applied to reach its conclusion is often impossible. Arguing against the logic of a neural network introduces a difficult new facet to standard patent prosecution.
If the agency does not mandate clear documentation detailing when and how SCOUT was used during the examination of a specific application, the resulting opacity could undermine public trust in the validity of issued patents.
Conclusion
The release of the SCOUT demonstration video confirms that advanced, multi-model artificial intelligence is now a tangible component (in alpha or beta testing) within the USPTO infrastructure. By offering access to top-tier models alongside specialized internal datasets, the agency is equipping its workforce with highly capable analytical instruments.
The stringent warnings and separated data environments demonstrate a clear awareness of the vulnerabilities associated with this technology. Training and monitoring is another story.
For the intellectual property community, observing how these tools shape the substance and speed of examination will be imperative. As these systems move deeper into daily operations, maintaining rigorous human oversight remains the most effective safeguard for the integrity of the patent system.
Disclaimer: This is provided for informational purposes only and does not constitute legal or financial advice. To the extent there are any opinions in this article, they are the author’s alone and do not represent the beliefs of his firm or clients. The strategies expressed are purely speculation based on publicly available information. The information expressed is subject to change at any time and should be checked for completeness, accuracy and current applicability. For advice, consult a suitably licensed attorney and/or patent professional.